Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification
Abstract
- fixed temporal convolution kernel depth대신 variable temporal convolution kernel depth를 사용하는 새로운 temporal layer를 제안한다.
- 2D DenseNet을 확장시킨 3D CNN에 새로운 temporal layer를 적용하여 T3D라는 새로운 네트웍을 제안한다.
- HMDB51, UCF101, Kinetics dataset에서 SOTA를 달성함
- pre-trained 2D CNN으로부터 3D CNN의 weight를 stable하게 initialization할 수 있는 transfer learning 방법을 제안함
1. Introduction
- 비디오에선 temporal information이 중요한데 이러한 정보를 잘 처리하기 위해 3D CNN을 많이 사용한다. 그러나 기존의 3D CNN은 long-range temporal information을 잘 다루지 못하거나 아래와 같은 문제가 있었다.
- 비디오 인식을 위한 3D CNN 아키텍처들은 2D ConvNet보다 더 많은 파라미터를 가지고 있다.
- 이러한 모델을 학습시키기 위해선 large labeled dataset이 필요하다.
- 성능을 더 높이기 위해 optical flow를 같이 사용하는 경우가 있는데 large scale dataset에선 그만큼 비용이 많이 든다.
- 위와 같은 문제점이 있지만 이를 보완할 수 있는 방법이 있다.
- 비디오에서 appearance와 temporal information을 잘 capture할 수 있는 효율적인 아키텍처가 필요하다. 이러한 정보를 잘 capture할 수 있다면 굳이 optical flow를 사용하지 않아도 된다.
- 서로 다른 아키텍처 간의 transfer learning을 통해서 네트웍을 처음부터 학습시켜야 하는 부담을 줄인다.
- 이와 같은 부분을 고려하여 deep spatio-temporal feature extractor network를 새롭게 제안한다.
- 제안하는 extractor는 3D conv kernel의 depth를 다양하게 모델링하여 shorter and longer time range에서도 temporal information을 잘 추출할 수 있다.
- 해당 레이어를 Temporal Transition Layer(TTL)이라 부르며 TTL은 서로 다른 temporal depth range로부터 추출된 temporal feature map을 concat하는 구조로 설계되었다. (즉 kernel depth를 고정된 값으로 사용하지 않고 여러 depth를 가지는 kernel을 사용한다.)
- back-bone network로는 2D DenseNet을 기반으로 하였다. DenseNet에서 기존의 2D Conv, Pooling을 모두 3D로 교체하였다. 논문에서는 이 네트웍을 DenseNet3D로 부른다.
- DenseNet을 선택한 이유는 파라미터 측면에서 효율적이기 때문이며, 기존의 DenseNet에 있던 Transition Layer를 TTL로 교체한 모델을 Temporal 3D ConvNets(T3D)라 부른다.
- T3D는 appearance와 temporal information 정보를 densely, efficiently하게 capture할 수 있으며 이는 short, mid, long-range term에서도 잘 작동한다.
또한 3D ConvNet을 large-scale dataset으로 처음부터 학습시키는 건 너무 오래걸리기 때문에 이미지넷으로 사전학습된 2D CNN을 teacher로 두고 랜덤하게 초기화된 3D CNN을 transfer learning으로 학습시킨다.
- 논문의 main contribution은 크게 2가지로 볼 수 있다.
- short, mid and long-range에서 temporal information을 잘 capture할 수 있는 TTL을 제안한다.
- 3D ConvNet을 효율적으로 학습시키기 위해 사전 학습된 2D CNN을 이용하여 transfer learning으로 학습시킨다.
2. Related Work
기존의 아키텍처들은 고정된 kernel depth를 사용하기 때문에 long-range temporal information을 잘 다루지 못한다.
⇒ 우리는 이러한 문제점을 variable temporal depth를 사용하여 해결한다.
transfer learning은 뉴럴넷을 효율적으로 학습시킬 수 있는 방법 중 하나인데 우리가 사용하는 transfer learning은 기존의 transfer learning과는 좀 다르다.
⇒ 우리는 2D CNN에서 3D CNN으로 supervision을 transfer하는 방식이며 다른 modality에서도 사용할 수 있다.
3. Proposed Method
- 우리의 goal은 short, mid, long term dynamic을 잘 capture하는 것이며 이를 위해 TTL을 제안한다.
- TTL의 output feature map은 뒷단에 있는 DenseBlock내의 모든 레이어에 입력으로 들어가게 된다.(DenseNet의 dense connectivity 구조)
2D CNN에서 3D CNN으로 supervision, knowledge를 transfer learning하여 3D CNN을 처음부터 학습시킬 필요가 없다.
### 3.1 Temporal 3D ConvNets
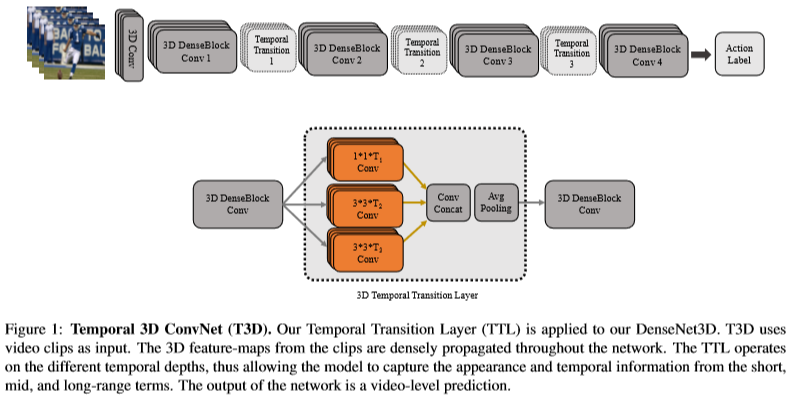
- DenseNet을 기반으로 하기 때문에 구조가 DenseNet이랑 비슷하다. 즉 Dense Block 내에서는 모두 dense connectivity 구조를 가지며 이전 레이어의 모든 feature map을 concat하여 다음 layer로 전달한다.
- TTL에서는 서로 다른 kernel depth를 가지는 커널을 사용하여 feature를 추출한 뒤 concat하는 구조를 갖는다. channel 축으로 concat하기 때문에 spatial size는 모두 같다.
- 따라서 TTL은 short, mid, long term dynamic를 잘 capture할 수 있으며 fixed depth를 사용한 커널에 비해 더 중요한 정보를 잘 추출하게 된다.
### 3.2 Supervision or Knowledge Transfer
- Goal: 3D CNN의 초기화를 잘 하자
- ImageNet으로 사전 학습된 2D CNN을 I, 랜덤 초기화된 3D CNN을 V라고 하면, I는 image로부터 rich representation을 학습했던 반면 V는 randomly initialized 됐기 때문에 I → V로 knowledge를 잘 전달하는 것이 목표이다. 따라서 수백만개의 파라미터를 가지는 V를 처음부터 학습할 필요가 없다.
- 제안하는 transfer learning은 같은 time stamp에서 frame과 video clip 사이의 correspondence를 사용하는 것
- 2D CNN은 image에서, 3D CNN은 video clip에서 feature를 추출함. 같은 시간대의 frame과 clip일지라도 3D CNN은 초기화가 제대로 안됐기 때문에 추출되는 feature의 semantic information이 부족할 것이다. 이를 2D CNN과 3D CNN에서 image video correspondence task로 놓고 해결하겠다는 것, 결국 mid-level feature representation을 더 효과적으로 학습하기 위함.
- 2D CNN에는 frame pair를 입력으로, 3D CNN에는 video clip을 입력으로 한다. 해당 frame과 clip이 같은 time stamp를 사용하면 frame과 clip은 결국 같은 정보를 의미하는 것이고 입력으로 들어가는 방식만 frame이냐 clip이냐 차이다.
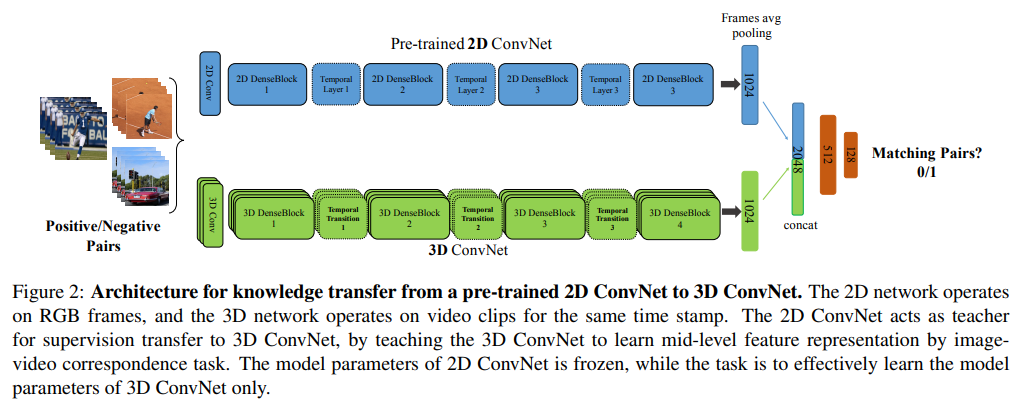
- 2D, 3D CNN에서 나온 각각의 크기가 1024인 feature vector를 concat하여 2048짜리 vector를 만들고 뒤에 512, 128짜리 f.c layer를 추가한 뒤 마지막에 binary-classifier layer를 사용한다.
- 주어진 frame pair가 video clip과 동일한 비디오에서 동일한 time stamp로부터 샘플링 된 경우 frame과 clip은 positive pair가 되고 서로 다른 비디오에서 샘플링된 경우 negative pair가 된다. 따라서 binary classifier는 frame pair가 video clip과 매칭되는지 아닌지 분류한다.
- 2D CNN으로 X개의 frame이 순차적으로 입력되고, 마지막 DenseBlock까지 들어간 다음 Flatten하든 GAP하든 vector로 만듦. 그러면 총 X개의 vector가 만들어지고 X개의 vector를 평균낸 vector를 1024 f.c로 연결
- For a given paired X-images and its corresponding video clip, the precise steps follows as, X frames are fed sequentially into the I and we average the X last 2D fc features, resulting into 1024-D feature representation
- 2D CNN과 병렬적으로 3D CNN에서는 video clip을 입력으로 받아 1024 vector를 만듦
- we extract the 3D fc features (1024-D), and concatenate them, which is then passed to fc1-fc2 for classification
- 학습 시 2D CNN은 프리징되고 V(3D CNN)만 학습된다. 추가적인 supervision 없이도 3D CNN의 parameter들이 효과적으로 학습되어 mid-level feature representation을 높일 수 있게 된다.
- 제안하는 transfer learning을 통해 3D CNN을 stable하게 weight initialization시킬 수 있음. 이렇게 초기화시키고 나서 target dataset으로 fine-tuning했을 때 모델이 target을 빠르게 adapt할 수 있었고 성능도 개선되었음.
- 따라서 제안하는 transfer learning을 통해 모델을 처음부터 학습시켜야 한다는 비용이나 부담을 줄일 수 있게 된다.
- 처음에 train하기 위해 YouTube8m dataset에서 약 500,000개의 unlabeled video clip을 사용.
- 제안하는 transfer learning은 unsupervised learning이기 때문에 별도의 video label이 필요 없음. 2D CNN의 input으로 들어가는 frame과 3D CNN의 input으로 들어가는 video clip이 same video & same time stamp에서 샘플링 됐으면 positive고 그렇지 않으면 negative. binary classification이기 때문에 positive인지 negative인지만 필요하고 video label 같은 건 필요 없음.
4. Experiments
4.1. Architecture Search
- 적절한 네트워크 아키텍처를 찾기 위해 네트워크의 사이즈, input data의 temporal-depth를 바꿔가며 search함
- TTL은 variable temporal kernel size를 사용하기 때문에 more informative spatial temporal feature를 추출할 수 있음
기존의 2D-DenseNet 121, 169 구조를 기반으로 3D convolution을 적용하고 TTL을 추가한 네트워크를 T3D-121, T3D-169로 정의함. 구조는 Table 1과 같다.
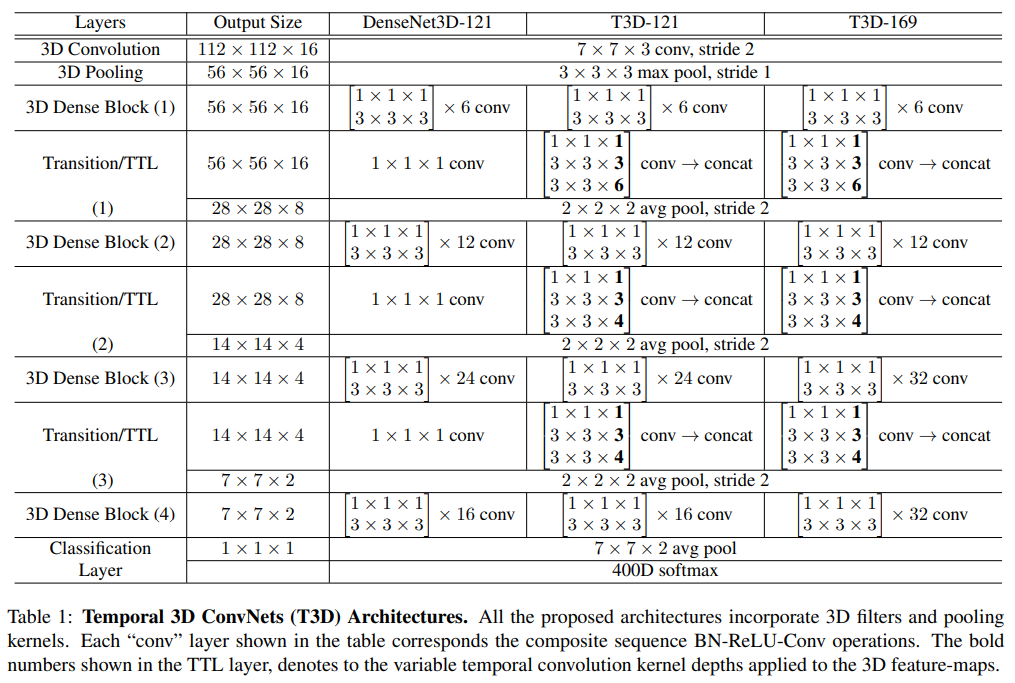
T3D-121, T3D-169를 UCF101 split 1 dataset으로 테스트해본 결과, 3D DenseBlock을 더 많이 사용하는 T3D-169가 조금 더 성능이 좋았음
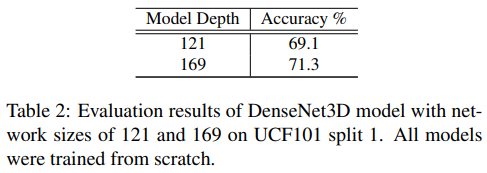
논문 앞쪽에서는 2D DenseNet에서 2D conv, pooling layer를 3D layer 바꾼 모델을 3D DenseNet이라 부르고, 여기에 TTL을 추가한 모델을 T3D라고 부른다고 했는데 Table 2의 DenseNet3D는 T3D를 의미함.
input data의 temporal depth가 activity recognition에서 중요한 key가 되기 때문에 이번에는 input data의 temporal depth를 다르게 주었을 때 성능이 얼마나 차이나는지 비교함.
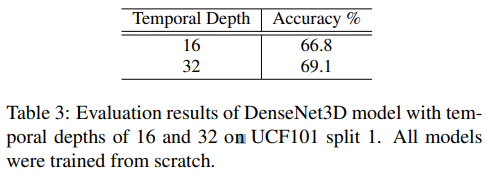
input data의 temporal depth가 더 깊은 경우 성능이 더 좋았음
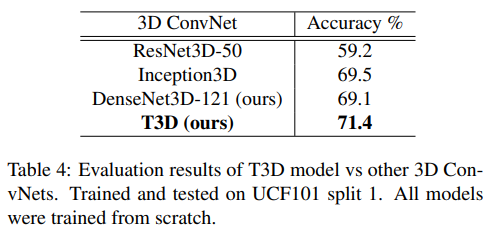
다른 SOTA 아키텍처과 비교하기 위해 ResNet50, Inception 모델의 2D layer를 3D layer로 교체한 뒤 본인들의 아키텍처와 성능을 비교함
4.2. Input Data
- 적절한 frame resolution을 찾기 위한 실험
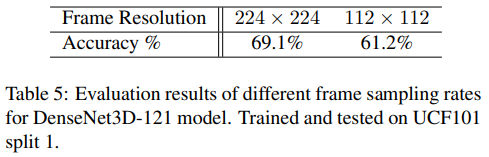
- frame resolution을 224x224, 112x112로 해봤을 때 역시 resolution이 큰 경우 성능이 더 높았다.
- 여기서 말하는 DenseNet3D-121은 T3D가 아니고 Table 1의 DenseNet3D-121 모델임..
- T3D로도 해봤는데 224x224가 더 좋더라
따라서 T3D를 Kinetics dataset으로 학습할 때 224x224 resolution을 사용하였다.
이번에는 frame sampling rate에 대한 실험
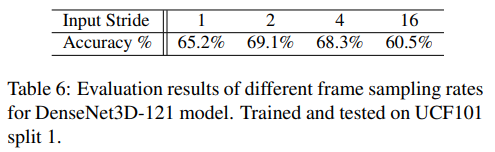
- Input frame의 temporal stride를 다르게 하여 evaluation
- 실험에서 사용되는 clip의 frame은 training / test 모두 32-frame사용. Input stride가 정확히 의미하는 게 무엇인지..?
4.3. HMDB51, UCF101, and Kinetics Datasets
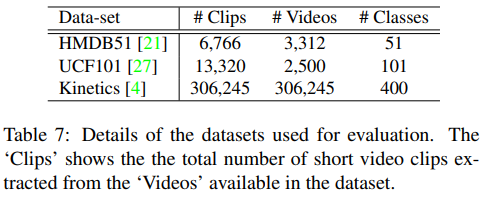
- 사용하는 Dataset의 정보
- UCF101, HMDB51 evaluation에서는 Kinetics dataset으로 먼저 학습시킨 다음 UCF101, MHDB51 dataset으로 fine-tuning
- Table 7의 “Clip”은 dataset의 video에서 추출한 short video clip으로 실제 network에 입력으로 들어가는 clip이 아님. 입력 clip은 저기서 다시 샘플링하여 더 작은 clip으로 만들어서 들어감.
4.4. Implementation Details
- Training
- Supervision Transfer: 2D → 3D CNNs
- SGD
- mini-batch 32
- weight decay 1e-4
- Nesterov momentum 0.9
- lr=0.1 and decrease by a factor of 10 every 30 epochs
- maximum epochs is 150
- Temporal 3D ConvNets
- train T3D from scratch on Kinetics
- resize video to 256x256, and then randomly 5 crops of size 224x224
- Supervision Transfer: 2D → 3D CNNs
- Testing
- decompose each video into non-overlapping clips of 32 frames
- take 224x224 center-crop
4.5. Supervision Transfer
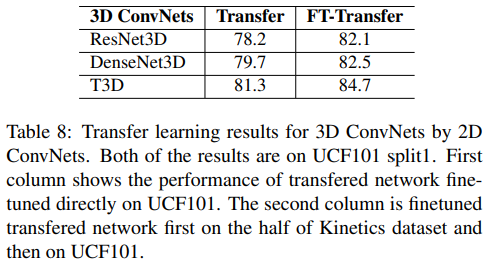
- 제안하는 transfer learning(YouTube8m dataset 사용)으로 3D CNN을 initialization한 뒤 UCF101 or Kinetics dataset으로 fine-tuning
- “Transfer” column은 UCF101 dataset으로 fine-tuning
- “FT-Transfer” column은 UCF101, Kinetics dataset 절반으로 fine-tuning
- ResNet, DensNet, T3D 3가지 아키텍처에서 T3D 구조가 성능이 가장 좋으며, FT-Transfer했을 때 accuracy가 가장 높음.
4.6. Comparison with the state-of-the-art
Kinetics dataset으로 다른 SOTA 모델들과 비교
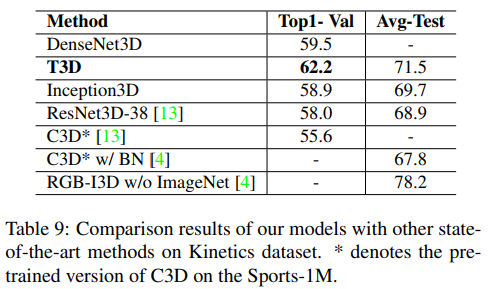
- 논문에서 제안하는 DenseNet3D와 T3D는 Inception3D, ResNet3D-38, C3D보다 성능이 잘 나옴.
그러나 RGB-I3D보다 성능이 뒤떨어짐. 그 이유는 T3D는 video clip이 32 frame인 반면 RGB-I3D는 64 frame을 사용했기 때문에 차이가 있음
- UCF101, HMDB51 dataset evaluation
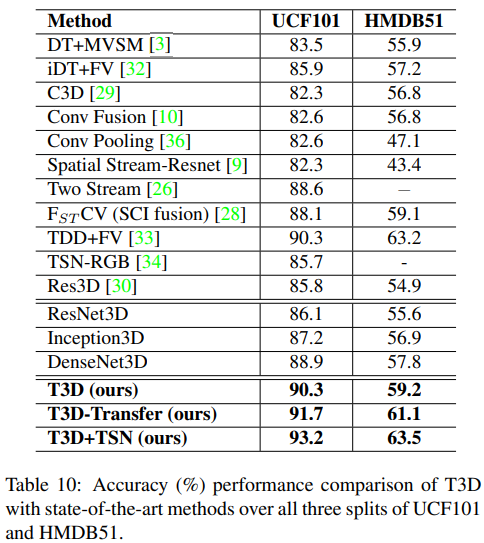
- 본 논문에서 제안하는 T3D, DenseNet3D은 ResNet3D, Inception3D, C3D보다 더 성능이 좋음
- optical flow를 사용하거나 long-term frame clip을 사용하는 모델들이랑 비교했을 때도 좋은 성능을 냄.
- TSN은 video clip으로부터 long term information을 encoding하는 method.
5. Conclusion
- variable temporal depth를 가지는 kernel을 사용하는 Temporal Transition Layer(TTL)을 새롭게 제안함
- fixed 3D homogeneous kernel depth를 사용하는 것보다 variable temporal kernel depth를 사용하는 것이 더 효과적임
- DensNet 아키텍처를 기반으로 Temporal 3D ConvNets(T3D)라는 모델을 설계함
- 제안하는 TTL의 feature map은 densely하게 propagation되며 end-to-end로 학습됨
- TTL feature map은 정보의 손실 없이 feature interaction을 더 expressive하고 efficient하게 모델링 할 수 있음
- T3D를 action recognition dataset으로 evaluate해본 결과 HMDB51, UCF101 dataset에서 SOTA를 달성하였으며 Kinetics dataset에서도 좋은 성능을 보여줌
- TTL은 다른 3D 아키텍처에도 사용하여 일반화 할 수 있음
- 아키텍처 간의 transfer learning을 통해 3D CNN을 처음부터 학습시켜야 하는 비용을 줄일 수 있으며 3D CNN을 stable하고 valuable한 weight initialization할 수 있음