Learning Spatiotemporal Features with 3D Convolutional networks
Intorduction
- 인터넷에서 멀티미디어의 폭발적인 성장으로 비디오를 분석하고 이해하는 것이 중요해졌다.
- 효과적인 video descriptor를 만들기 위해선 4가지 특성을 잘 고려해야 한다.
it needs to be generic
⇒ 여러 종류의 비디오를 잘 분석할 수 있어야 한다.
video descriptor needs to be compact
⇒ 비디오가 너무 많기 때문에 compact한 descriptor가 processing이나 storing 측면에서 도움이된다.
it needs to be efficient to compute
⇒ real world에선 분당 수천개의 비디오가 처리되기 때문에 효율적인 연산이 필요하다.
it must be simple to implement
⇒ good descriptor는 구조가 복잡하지 않고 simple하면서도 잘 작동해야 한다.
- Deep 3D CNN을 사용하여 spatio-temporal(시공간) feature를 잘 학습할 수 있는 방법을 제안한다.
- 주요 contribution은 다음과 같다.
- 3D CNN은 model appearance와 motion을 동시에 잘 학습할 수 있다.
- 모든 레이어에서 3x3x3 커널을 사용하는 것이 가장 best
- proposed feature와 simple linear model을 같이 사용했을 때 성능이 좋았다.
Related Work
- 이전에 다양한 연구에서 여러가지 방법을 제안해왔지만 대부분 공통적으로 computation 측면에서 intensive하고 large scale dataset에 적용하기 어렵다는 문제가 있음
- 우리가 제안하는 방법은 비디오의 전체 프리엠을 입력으로 하고 어떤 전처리 과정에 의존하지 않음
- 우리는 2D Conv가 아닌 3D Conv와 3D Pooling을 사용하여 temporal 정보의 propagation이 잘 이루어지도록 함
Learning Features with 3D ConvNets
3D convolution and pooling
- 2D convolution은 spatial 정보만 추출하기 때문에 비디오 같은 시공간적 정보가 같이 포함된 데이터에서 temporal 정보를 추출할 수 없다.
- 이에 반해 3D convolution은 커널의 sliding 방향이 3차원이기 때문에 spatial 정보뿐만 아니라 temporal 정보까지 같이 다룰 수 있게 된다. 따라서 3D convolution, 3D pooling을 사용하는 것이 더 적합하다.
- 2D Conv vs 3D Convs
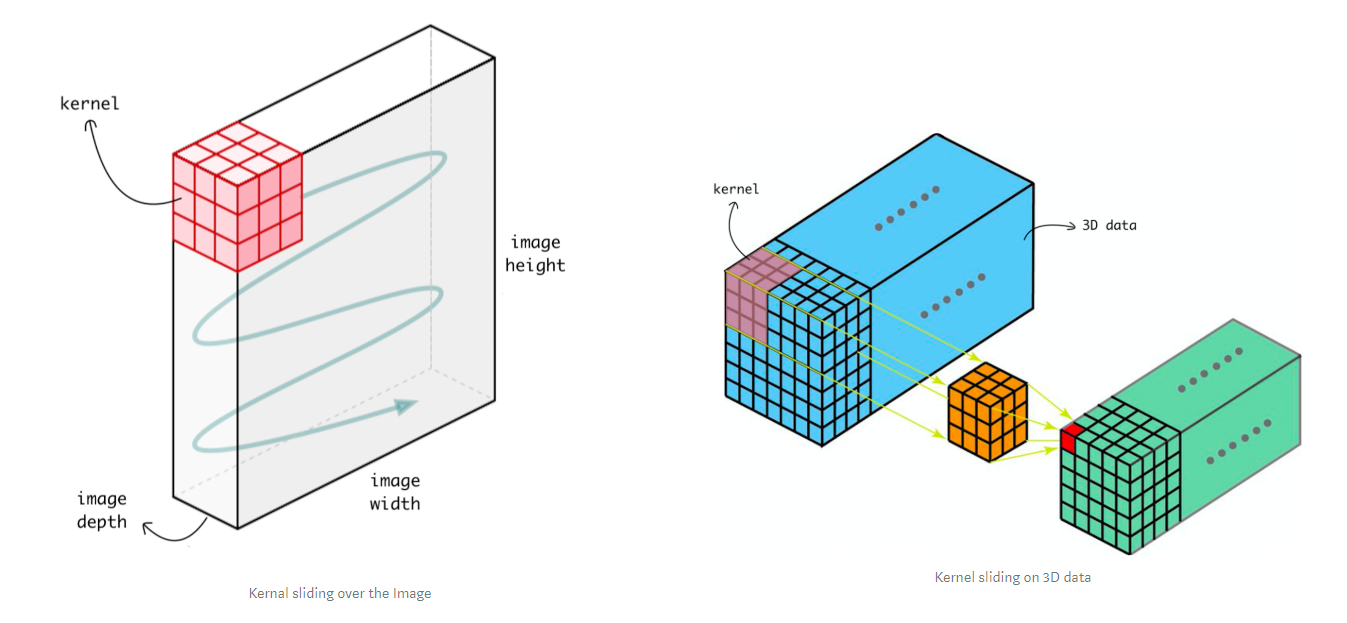
https://towardsdatascience.com/understanding-1d-and-3d-convolution-neural-network-keras-9d8f76e29610
- 3D Conv를 사용하는 효과적인 네트워크 아키텍처 finding
- deep network를 large-scale video dataset으로 학습시키는데 시간이 너무 많이 걸림
- medium-scale dataset인 UCF101 데이터셋을 사용하여 best architecture를 search 한 뒤에, 해당 구조가 large scale dataset에서도 쓸만한지 검증함
- 커널은 3x3 filter를 사용하되 temporal information을 추출하기 위한 kernel의 depth를 바꿔가며 실험
- 오버랩되지 않은 16 frame을 하나의 clip으로 사용
- 모든 conv layer에서 적절한 padding 값을 주고 stride=1로 하여 input과 output 사이즈가 달라지지 않게 함
- first pooling layer에서만 1x2x2 사용함 초기에 temporal information를 merge하지 않고 clip의 frame 수를 16으로 유지하기 위함, 그 이후 pooling layer에서는 stride=1인 2x2x2 max pooling 사용함 pooling layer 거치면 output feature 사이즈는 input feature size에 비해 8배 줄어듦
Varying network architectures
- 좋은 네트워크 아키텍처를 서치할 때 커널의 depth만 변화시키고 다른 값은 고정함
- 2가지 타입의 아키텍처를 실험함
homogeneous temporal depth
⇒ 모든 컨볼루션 레이어에서 동일한 depth의 커널을 사용
⇒ 커널의 depth가 1, 3, 5, 7로 고정된 4개의 네트웍을 만들어 실험함, 논문에서 이 네 트웍을 depth-d로 부름
varying temporal depth
⇒ 레이어별로 커널의 depth를 다르게 설정하는 것
⇒ increasing(3-3-5-5-7), decreasing(7-5-5-3-3) 2개의 타입으로 실험
- 커널의 depth에만 변화를 주었기 때문에 컨볼루션 레이어의 파라미터만 서로 상이함
Exploring kernel temporal depth
- 위에서 제시한 네트웍 아키텍처를 UCF101 dataset의 split 1으로 실험함
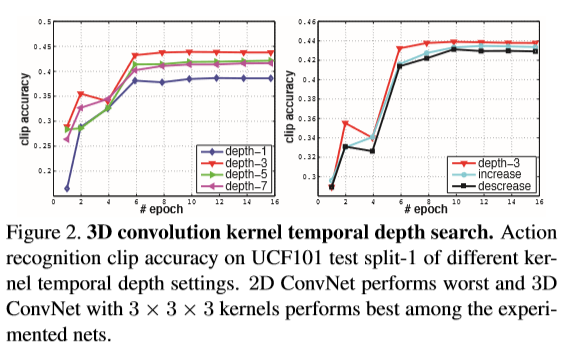
- left: homogeneous, right: changing depth
- 아키텍처 중 depth-3가 성능이 가장 좋았으며 I380K라는 내 large-scale dataset으로 실험해본 결과 3D ConvNet이 2D ConvNet보다 성능이 더 좋았다.
Spatiotemporal feature learning
- 아키텍처 서칭에서 3x3 homogeneous depth-3가 가장 성능이 좋았음을 확인했다.
- 위와 같은 구조로 8 conv layer, 5 pooling layer, 2 f.c layer, sortmax layer로 네트워크를 구성하였다.

- 위와 같은 구조의 네트워크를 C3D라 부른다.
- 모든 conv layer에서 3x3x3 kernel, 1x1x1 stride를 사용한다.
3D pooling에서 첫번째 pooling layer만 1x2x2 kernel, 1x2x2 stride를 사용하며 나머지 pooling layer에서는 모두 2x2x2 kernel, 2x2x2 stride를 사용한다.
⇒ 첫번째 pooling layer에서만 다른 사이즈를 사용하는 이유는 네트워크 앞단에서는 temporal information을 보존하기 위함
- C3D로 patiotemporal feature를 학습하기 위해 Sports-1M dataset을 사용한다. 이 데이터셋은 video classification benchmark에 사용되는 데이터셋으로 1.1 million 개의 비디오, 487개의 카테고리로 구성되어 있다. UCF101 데이터셋과 비교했을 때 비디오 수가 100배, 카테고리 수가 5배 이상 큰 데이터셋이다.
- 비디오가 크기 때문에 training video에서 2초짜리 clip을 5개를 랜덤추출하고 프레임 사이즈를 128x171로 리사이징 한다.
트레이닝 시 input clip을 16x112x112로 spatial and temporal jittering한다.
⇒ ?
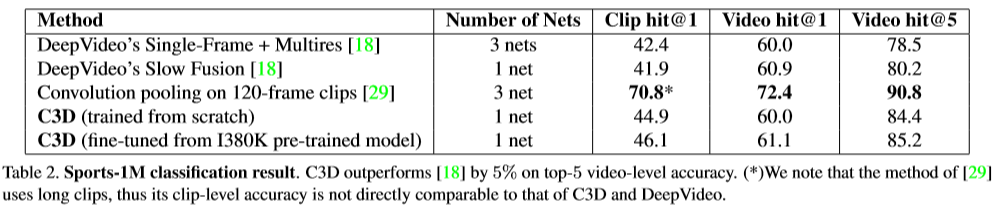
- 실험 결과에서 다른 모델과 비교할 때 고려해야 할 점
- Deep Video는 clip 당 4번 crop하고 video 당 80번 crop한다. 이에 반해 C3D는 clip당 1번 crop하고 video당 10번 crop한다는 점
- 그럼에도 불구하고 처음부터 학습시켰을 때 84.4%, fine-tuning 했을 때는 85.2%를 달성함 (논문에서는 85.2%가 아닌 85.5%라고 언급하는데 오타인지(?))
- 그러나 [29] 모델보다 성능이 낮은데 그 이유는 해당 비교 모델은 한 clip이 120 frame이기 때문에 성능이 좋을 수밖에 없고 상대적으로 적은 수의 frame을 1 clip으로 사용하는 C3D와 직접적으로 비교하기에는 무리가 있다.
- 이렇게 학습된 C3D는 다른 비디오 task에서 feature extractor로 사용될 수 있음
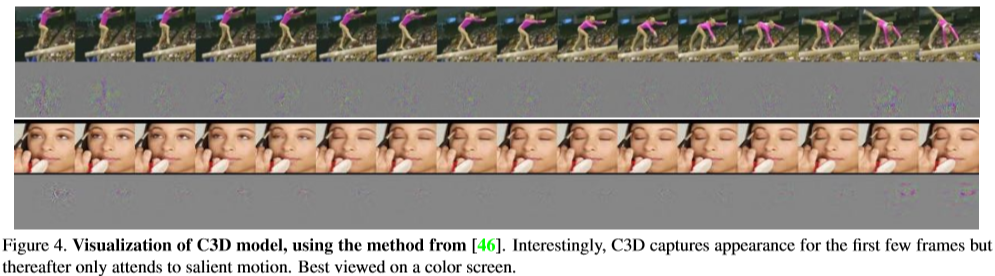
- C3D는 무엇을 학습하는지 이해하고자 deconvolution method를 사용하였음. 그 결과, 초기 프레임에서는 appearance를 이후 프레임에서는 salient motion에 집중한다는 것을 알게됨
- 처음에는 사람 전체의 모습에 focus하다가 그 이후에는 motion에 focus
- 즉 C3D는 motion과 appearance를 선택적으로 취한다는 점에서 2D ConvNet이랑 명확한 차이가 있다.
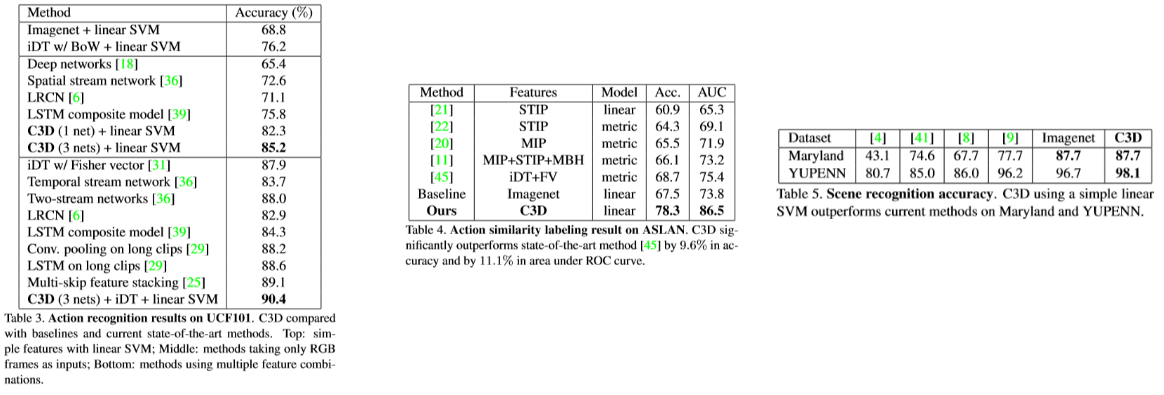
- 또한 C3D를 “Action recognition”, “Action Similarity Labeling”, “Scene and Object Recognition”에 적용해봤을 때도 매우 우수한 성능을 보여줌
Conclusions
- 3D ConvNet을 이용하여 video의 spatiotemporal feature를 효과적으로 추출하고 large-scale video dataset에서도 활용
- 3x3x3의 best temporal kernel length를 find함
- C3D는 appearance와 motion information을 동시에 모델링할 수 있으며 2D ConvNet 보다 우수한 성능을 냄